行业 来源:壹点网 时间:2022-10-31 11:02:24
典型应用场景、负载与需求
时序数据库往往在金融与物联网领域发挥重要作用。物联网行业中,高频写入亿级设备数据、对写入数据自动去重、点查少量设备数据、以及统计分析大量设备数据都是比较常见的应用场景;金融行业中,实时写入股票数据、对单只股票进行毫秒级点查、以及对大量股票进行统计分析与回测也需要高性能时序数据库的支持。

研发人员参考上述典型应用场景,设计时序数据库时会考虑如下因素:
▪时序数据库面临极高的实时写入负载,可达数亿条每秒;
▪时序数据库面临较高的查询负荷;
▪时序数据往往少量更新,经常批量删除;
▪控制成本。
因此,在设计 DolphinDB 数据库时,我们采取了区别于传统 OLTP 数据库的思路。
性能大PK
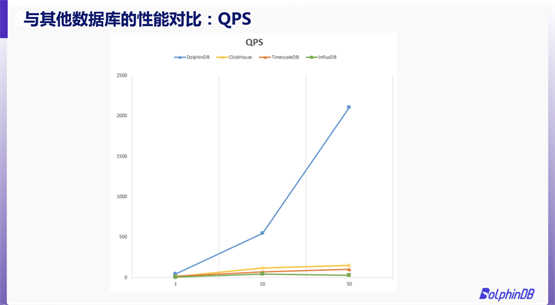
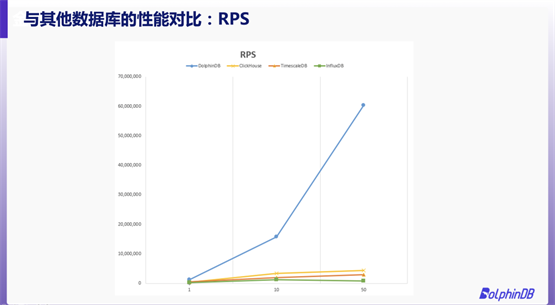
与市面上的热门时序数据库相比,DolphinDB 的性能究竟如何?我们用测试数据说话。
我们选择了 NYSE Exchange TAQ Historical Data 作为测试数据,选取 2007 年 8 月和 9 月的 Quotes 数据文件,原始数据大小为430 GB。我们采取点查的方式,查询某一只股票一天的原始数据。事先随机生成 100,000 条 SQL,所有数据库按顺序从集合中读取 SQL。
本次测试中,我们重点关注 QPS(Query Per Second)与 RPS(Record Per Second)结果。通过图片不难发现,DolphinDB 的 QPS 和 RPS 均远远领先 ClickHouse、TimescaleDB 与 InfluxDB。在50个线程下并发查询时,DolphinDB的 QPS 甚至可以达到其他数据库的10倍以上。可以说,DolphinDB的存储引擎高度适配了点查的应用场景。
WHY LSMT?
总体来说,数据库的存储引擎有两大类解决方案:基于 page 和 B+ 树的解决方案,与基于 Log Structured Merge Tree 的解决方案。之所以 LSMT 架构更适合时序数据的处理,是因为它具有以下特点:
▪LSMT 能够转随机写为顺序写,能低成本承受极高的实时写入负载;
▪LSMT 可对 SortKey 进行排序,连续存储同一条时间线的数据,提高后续点查效率;
▪LSMT 的数据文件不会繁琐零碎,能够高效支持大规模统计分析。
TSDB 设计详解
基于 LSMT 架构,DolphinDB 推出了自研新存储引擎 TSDB。TSDB 架构设计如下图。
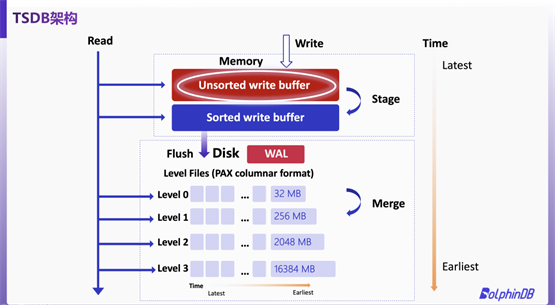
TSDB在存储数据时,将数据拆分成多个数据块(block),若查询一条数据,则只需解压该条数据所在的数据块,从而提升查询效率。
事务支持、数据去重以及高频更新
TSDB 支持基于快照隔离的事务。在每条数据写入时记录其版本号,查询时仅查询某版本号之前的数据,因此保证用户读到的数据一致。
工业物联网场景中,某个设备往往会在同一时间戳下产生多条数据。若数据乱序程度不大,重复数据会存储在内存中,在刷盘时对数据进行排序及去重。如果数据乱序程度很大,TSDB 则会在查询时去重。总体而言,去重对查询性能的影响微乎其微。
而在 LSMT 架构中,数据总是从上到下写入的,这与时序数据的时间戳递增的特性完美符合。TSDB 根据 LSMT 的这一特点,将更新的数据转为追加写,写入到内存中,满足高频更新需求。
时间线膨胀问题该怎么解决?
当时间线非常多,而数据又非常稀疏(即每条时间线的数据很少)的时候,由于数据很碎片化,写入和查询的速度都会变慢、压缩和大规模分析的效率也会降低。
TSDB 解决时间线膨胀的核心思路是“减少”时间线。具体来讲,就是引入了一个新的参数 sortKeyMappingFunction,让用户可以提供一个函数(或自定义的,或 DolphinDB 内嵌的函数,如 hashBucket 函数),以此起到降维的效果。
不只是存储
为了更好地挖掘并利用数据的价值,DolphinDB 为用户提供了一站式分布式计算解决方案。用户可以直接使用 SQL 进行分布式查询,能够灵活调用内置的1400余个分析函数。同时,DolphinDB 的编程语言简单易用,代码简洁且易于维护。
免责声明:市场有风险,选择需谨慎!此文仅供参考,不作买卖依据。
标签:







